Next 블로그 seo 최적화 하기

잘못된 내용이 있으면 댓글을 달아주세요.
SEO
SEO 는 serach engine optimazation 의 준말입니다. 말 그대로 검색엔진 최적화라는 의미이며 웹사이트를 네이버, 구글과 같은 검색엔진에 노출이 더 잘되도록 만드는 작업이라고 할 수 있습니다. 저는 블로그를 next 환경에서 개별적으로 만들었고, 따라서 블로그를 노출시키기 위해서는 seo 최적화가 필요했습니다.
seo 최적화를 하는 방법은 다양하지만, 이번에는 title, meta 태그 와 sitemap 을 적용하는 방법을 진행했습니다.
title 태그 사용하기

title 태그는 브라우저 탭에 표시되며 본문 컨텐츠에서는 표시되지 않는 태그입니다. title 태그는 사용자는 물론 검색엔진에 특정 페이지의 주제가 무엇인지 알려줍니다. title 태그는 위 처럼 브라우저의 탭에 표시됩니다.
title 작성하기
✅ 이렇게 사용하세요.
- 타이틀 태그는 페이지의 컨텐츠를 정확하게 설명해야하고 최대한 간결해야합니다.
- 타이틀 태그는 모든 페이지에 고유한 타이틀로 사용되어야 합니다.
- 구분자로
|,:이 사용될 수 있습니다.
❌ 이렇게 사용하지 마세요.
- 페이지와 관련이 없거나 무의미한 타이틀을 등록합니다.
- 매우 긴 텍스트 또는 본문 전체를 사용합니다.
- 사이트의 페이지 또는 여러 페이지에 단일한 제목을 사용합니다.
저는 이런 title 태그의 사용을 위해 SEO 라는 컴포넌트를 만들었습니다.
import Head from "next/head"; // title, meta 태그를 사용하기 위해 불러옵니다. const SEO = (props) => { return ( <Head> <title>오터 로그</title> </Head> ); }; export default SEO; // 우선 index 페이지에 적용되는 SEO 컴포넌트를 만들 예정이어서 props를 사용하지 않았습니다.
Meta 태그 사용하기
meta 태그는 검색엔진에 페이지의 내용을 요약하여 제공하는 태그입니다. 페이지의 제목은 단어나 문구로 이루어질 수 있지만 페이지의 메타설명 태그는 길어질 수 있습니다.
meta 태그는 검색엔진에서 메타 태그를 페이지의 스니펫으로 사용할 수 있기 때문에 중요합니다. 또한, 카카오톡이나 트위터 등에 해당 게시글을 공유할 때에도 중요한 역할을 합니다.

위처럼 공유를 할때 보여주고 싶은 내용을 설정할 수 있기 때문입니다.
Meta 태그의 종류
🖇️. name=”author”
문서의 저자를 명시합니다.
<meta name='author' content='otter' /> // 저는 간단히 제 닉네임을 사용했습니다.
🖇️. name=”description”
<meta name='description' content='프론트엔드를 공부하는 오터의 기록들' /> // 해당 페이지의 내용을 소개합니다. // 일단 index 페이지를 기반으로 작성했습니다.
meta name='description 태그는 검색엔진에서 스니펫으로 사용될 가능성이 있어 중요합니다.
구글 seo 가이드에 따르면 다음과 같이 작성해야합니다.
✅ 이렇게 사용하세요.
-
페이지마다 고유한 설명을 작성해야 합니다.
-
설명에 컨텐츠 관련 정보를 포함해야 합니다.
문장형식이 아니어도 괜찮습니다. (ex -
저자: otter, 내용: Seo) -
정확한 설명을 제공해야 합니다.
❌ 이렇게 사용하지 마세요.
-
키워드로 작성합니다.
<meta name="description" content="재봉용품, 털실, 색연필, 재봉틀, 실, 보빈, 바늘"> -
다른 페이지에도 동일한 설명을 작성합니다.
-
너무 짧거나 구체적이지 않습니다.
(reference : 우수한 메타 설명을 만들기 위한 권장사항 )
🖇️. name=”viewport”
브라우저에 표시되는 화면에 대한 기준을 정해주는 태그입니다. 특히 모바일 디바이스와 관련해 뷰포트가 달라질 수 있으므로, 설정해주는 것이 좋습니다.
<meta name='viewport' content='width=device-width, initial-scale=1.0' /> // content = 뷰포트를 설정합니다. // width=device-width의 뜻은, 뷰포트의 너비를 device의 width로 한다는 이야기입니다. // initial-scale은 처음 로드될때의 확대-축소 레벨을 설정합니다. // 이를 통해 줌의 확대-축소를 막을수도 있지만 저는 코드라인이 많이 삽입되고 // 확대가 불가능하다면 접근성측면에서 좋지 않을것이라 생각해 추가하지 않았습니다.
🖇️. name=”keywords”
키워드는 페이지의 주요 키워드를 작성하는 부분이었으나, 최근에는 사용하지 않는다고 해서 추가하지 않았습니다.
(reference: 메타 키워드(meta keywords)는 SEO에 의미가 없습니다. )
🖇️. name=”robots”
robots 는 해당 페이지를 검색결과에 표시할지, 표시하지 않을지를 결정합니다.
그리고 페이지안에 있는 링크를 따라 이동하게 할것인지 아닌지를 지정할 수 있습니다.
- index : 검색결과 표시
- noIndex : 검색결과 미표시
- follow : 링크를 따라 이동
- nofollow: 링크를 따라 이동하지 않음
기본적으로 index, follow 로 설정이 되어 있으므로 따로 설정하지 않았습니다. 페이지가 검색결과에 노출되는 것이 목적이었기 때문입니다.
다만, 관리자용 페이지로 사용할 예정인 페이지가 존재해 해당 페이지의 meta 에는 noindex 로 설정해주려고 합니다.
위의 meta 태그들을 합쳐, SEO 컴포넌트를 다음과 같이 수정했습니다.
const SEO = (props: any) => { return ( <Head> <title>오터 로그</title> <meta name='viewport' content='width=device-width, initial-scale=1.0' /> <meta name='author' content='otter' /> <meta name='description' content='프론트엔드를 공부하는 오터의 기록입니다. Javascript, React, Next와 단위테스트를 위주로 공부하고 있습니다. ' /> </Head> ); };
Open Graph, og 태그 사용하기

오픈 그래프는 페이지를 카카오톡이나, 페이스북 등에 공유될때 위처럼 표시되는 미리보기입니다.
이 또한 meta 태그를 이용해서 설정할 수 있습니다.
<meta property='og:url' content='www.youtube.com' /> // 페이지의 url을 설정합니다. <meta property='og:title' content='YouTube' /> // 페이지의 이미지를 설정합니다. <meta property='og:description' content='여기를 눌러 링크를 확인하세요.' /> // 페이지의 description을 설정합니다. <meta property='og:type' content='article' /> // 페이지의 컨텐츠 타입을 설정합니다. <meta property='og:image' content='/public/example.png' /> // 이미지를 설정합니다. <meta property='og:image:alt' content='' /> // 이미지의 대체 텍스트를 설정합니다. <meta property="og:image:width" content="1200" /> <meta property="og:image:height" content="630" /> // 이미지의 크기를 설정할 수 있습니다. <meta property="og:locale" content="en_GB" /> // 페이지의 언어를 설정합니다.
덧붙여 위에 설정한 og 태그는 페이스북 공유 디버거 에서 확인해보실수도 있습니다.
저는 위와 같은 태그를 이용하 다음과 같이 마무리했습니다.
const SEO = () => { return ( <Head> ... < -- og tag -- > <meta property='og:url' content='https://otter-log.world' /> <meta property='og:title' content='오터 로그' /> <meta property='og:description' content='프론트엔드를 공부하는 오터의 기록입니다. Javascript, React, Next와 단위테스트를 위주로 공부하고 있습니다.' /> <meta property='og:image' content='https://res.cloudinary.com/ddzuhs646/image/upload/v1675164645/blog/daa778c3-734e-4d57-bca7-7e067dffbb9d/daa778c3734e4d57bca77e067dffbb9d.jpg' /> <meta property='og:image:alt' content='오터로그 이미지' /> <meta property='og:type' content='article' /> <meta property='og:locale' content='ko_KR' /> < -- twitter를 위해 추가한 부분 -- > <meta name='twitter:card' content='summary' /> <meta name='twitter:title' content='오터 로그' /> <meta name='twitter:description' content='프론트엔드를 공부하는 오터의 기록입니다. Javascript, React, Next와 단위테스트를 위주로 공부하고 있습니다.' /> <meta name='twitter:image' content='https://res.cloudinary.com/ddzuhs646/image/upload/v1675164645/blog/daa778c3-734e-4d57-bca7-7e067dffbb9d/daa778c3734e4d57bca77e067dffbb9d.jpg' /> </Head> ); };
(reference : Open Graph Meta Tags: Everything You Need to Know )
Canonical Tag
캐노니컬 태그란 사이트 내 URL 주소는 다르지만 동일한 내용의 중복된 페이지가 있을 때 페이지에 코드를 삽입하여 검색엔진에 대표가 되는 URL 주소를 알려주는 역할을 하는 태그입니다.
그런데, 저처럼 소규모의 블로그를 위해 seo 를 이용하시는 분들은 중복되는 페이지가 없다고 생각하실 수도 있습니다. 그렇지만, 검색엔진은 웹 페이지가 아닌 url 을 크롤링합니다.
https://www.bbclothing.co.uk/en-gb/clothing/shirts.html // 기본 url https://www.bbclothing.co.uk/en-gb/clothing/shirts.html?사이즈=XL // 쿼리가 추가된 url https://www.bbclothing.co.uk/en-gb/clothing/shirts.html ?Size=XL&color=블루 // 쿼리가 추가된 url
위의 상황에서 세개의 페이지는 쿼리문에 따라 분기되고, 약간만 다른 페이지만 검색엔진의 입장에서는 모두 별도의 페이지입니다. 따라서 중복적인 페이지라고 볼 수 있습니다. 이 외에도, 카테고리에 따라 달라지는 페이지이거나 다양한 장치 유형에 대한 페이지 등 또한 중복 페이지라고 할 수 있습니다.
이러한 경우에 canonical tag 를 사용해야 합니다.
✅ 이렇게 사용하세요.
-
절대 URL을 사용합니다.
https://example.com/sample-page/ -
https를 사용합니다.
-
페이지당 하나만 사용합니다.
-
head태그 내에서 사용합니다.
❌ 이렇게 사용하지 마세요.
-
상대 URL을 사용합니다.
/sample-page/ -
http를 사용합니다.
http://example.com/sample-page/ -
한 페이지에 여러개를 사용합니다.
검색엔진은 두개 이상의 canonical tag를 발견하면 무시합니다.
-
head태그 밖에서 사용합니다.
저는 위와 같은 기준을 따르며, 다음과 같이 구현했습니다.
<link rel=“canonical” href=“https://otter-log.world” />
(reference : Canonical 태그: 초보자를 위한 간단한 가이드 )
이를 추가해 최종적인 SEO 컴포넌트는 다음과 같습니다.
import Head from "next/head"; const SEO = () => { return ( <Head> <title>오터 로그</title> <meta name='viewport' content='width=device-width, initial-scale=1.0' /> <meta name='author' content='otter' /> <meta name='description' content='프론트엔드를 공부하는 오터의 기록입니다. Javascript, React, Next와 단위테스트를 위주로 공부하고 있습니다. ' /> <meta property='og:url' content='https://otter-log.world' /> <meta property='og:title' content='오터 로그' /> <meta property='og:description' content='프론트엔드를 공부하는 오터의 기록입니다. Javascript, React, Next와 단위테스트를 위주로 공부하고 있습니다.' /> <meta property='og:image' content='https://res.cloudinary.com/ddzuhs646/image/upload/v1675164645/blog/daa778c3-734e-4d57-bca7-7e067dffbb9d/daa778c3734e4d57bca77e067dffbb9d.jpg' /> <meta property='og:image:alt' content='오터로그 이미지' /> <meta property='og:type' content='article' /> <meta property='og:locale' content='ko_KR' /> <meta name='twitter:card' content='summary' /> <meta name='twitter:title' content='오터 로그' /> <meta name='twitter:description' content='프론트엔드를 공부하는 오터의 기록입니다. Javascript, React, Next와 단위테스트를 위주로 공부하고 있습니다.' /> <meta name='twitter:image' content='https://res.cloudinary.com/ddzuhs646/image/upload/v1675164645/blog/daa778c3-734e-4d57-bca7-7e067dffbb9d/daa778c3734e4d57bca77e067dffbb9d.jpg' /> < -- canoical tag 추가 -- > <link rel='canonical' href='https://otter-log.world' /> </Head> ); };
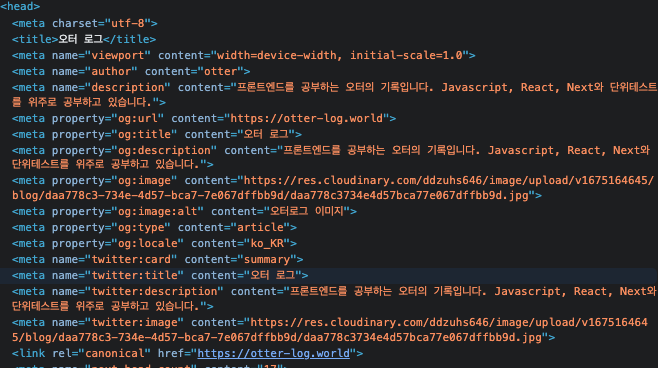
위처럼 잘 적용되었음을 확인할 수 있습니다.
사이트맵 만들기
사이트맵은 사이트에 있는 페이지, 동영상 및 기타 파일과 그 관계에 관한 정보를 제공하는 파일입니다. Google과 같은 검색엔진은 이 파일을 읽고 사이트를 더 효율적으로 크롤링합니다. 사이트맵은 내가 사이트에서 중요하다고 생각하는 페이지와 파일을 Google에 알리고 중요한 관련 정보를 제공합니다.
yarn add next-sitemap // next-sitemap 라이브러리를 이용할 수 있습니다.
블로그를 사용하면서 저는 isr 로 수정사항을 계속해서 추가하고 있습니다. 이를 위해서 공식문서에 나온 다음과 같은 방법을 이용했습니다.
(reference : Generating dynamic/server-side sitemaps )
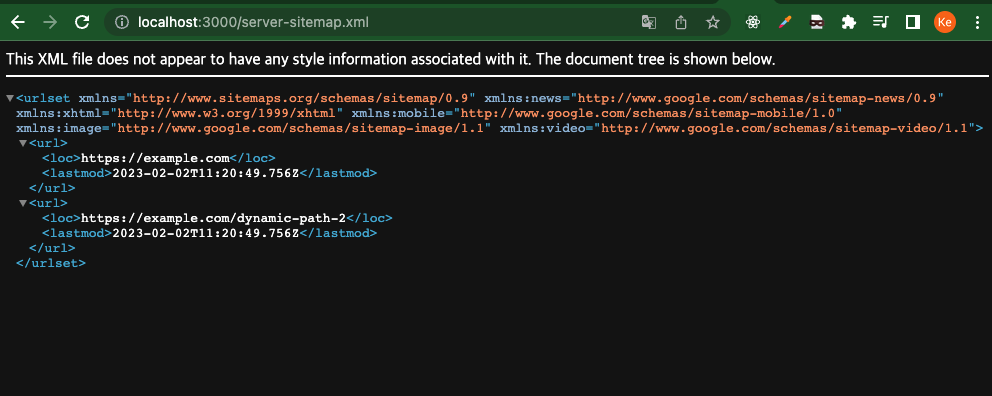
// pages/server-sitemap-index.xml/index.tsx // pages 폴더에 위의 이름으로 페이지를 하나 더 작성합니다. import { getServerSideSitemapIndex } from 'next-sitemap' import { GetServerSideProps } from 'next' export const getServerSideProps: GetServerSideProps = async (ctx) => { // getServerSideProps이기 때문에, 이 url에 접속할 때 데이터페치가 새롭게 이루어져 // 지속적으로 사이트맵을 최신화할 수 있습니다. // const urls = await fetch('https//example.com/api') const fields = [ { loc: 'https://example.com', // Absolute url lastmod: new Date().toISOString(), // changefreq // priority }, { loc: 'https://example.com/dynamic-path-2', // Absolute url lastmod: new Date().toISOString(), // changefreq // priority }, ] return getServerSideSitemap(ctx, fields) } // Default export to prevent next.js errors export default function SitemapIndex() {}
이 상태에서, 해당 url 로 접속하면 아래와 같은 sitemap.xml 이 생성되었음을 확인할 수 있습니다.
저는, notion API 를 사용하고 있었기 때문에 해당 api 로 모든 slug 들을 모아 다음과 같이 적용했습니다.
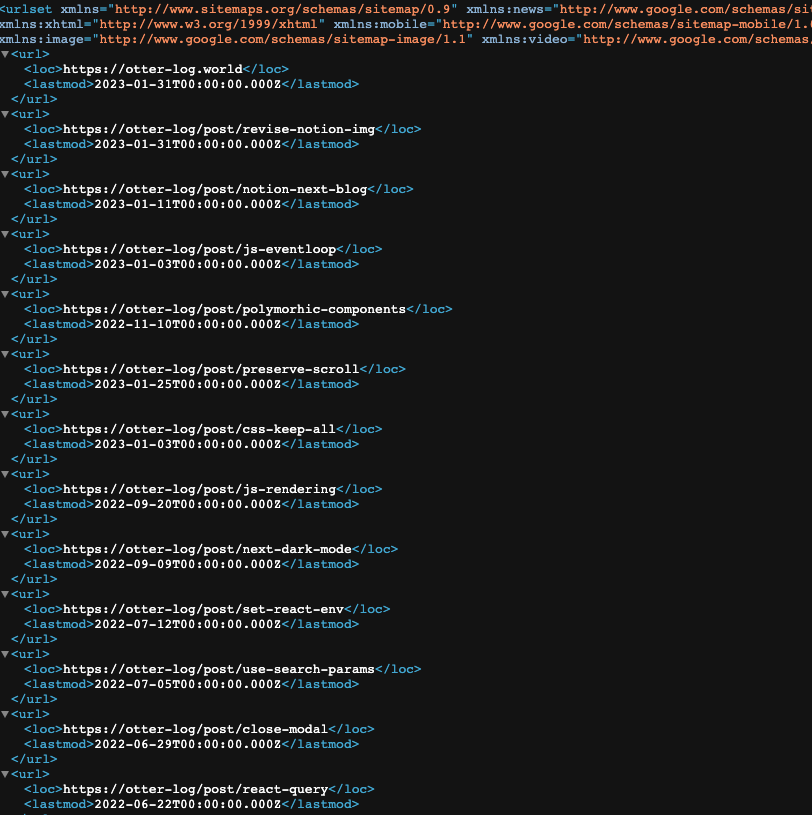
import { getServerSideSitemap } from "next-sitemap"; import { GetServerSideProps } from "next"; import { getAllPublished } from "lib/notion"; import { MetaData } from "types/types"; export const getServerSideProps: GetServerSideProps = async (ctx) => { const DATA_BASE_ID = process.env.DATABASE_ID as string; const data = await getAllPublished(DATA_BASE_ID); const dynamicFields = data.map((item: MetaData) => { return { loc: `https://otter-log/post/${item.slug}`, lastmod: new Date(item.last_mod).toISOString(), }; }); // notion API를 통해 slug들을 모아 필드를 만들고, const LAST_MODIFIED = dynamicFields[0].lastmod; // 첫번째 파일이 가장 늦게 등록된 파일입니다. const absoluteFields = { loc: "https://otter-log.world", lastmod: LAST_MODIFIED, }; // 현재 absoluteFields는 메인 페이지밖에 없으므로, 이를 적어주었습니다. const fields = [absoluteFields, ...dynamicFields]; return getServerSideSitemap(ctx, fields); }; // Default export to prevent next.js errors export default () => {};
그리고, 공식문서에 따라 next-sitemap.config.js 도 수정합시다.
module.exports = { siteUrl: "https://example.com", generateRobotsTxt: true, exclude: ["/server-sitemap.xml"], // 자동생성되는 server-sitemap-index.xml 은 제외합니다. robotsTxtOptions: { additionalSitemaps: ["https://otter-log.world/server-sitemap-index.xml"], // 이 경로에서 sitemap을 제공합니다. }, };
모든 과정을 마치고, url/server-sitemap-index.xml 이 접속해보면 아래와 같은 사이트맵을 확인할 수 있습니다.
구글 서치 콘솔 등록하기
이 부분은, 확인을 위한 부분이니 새롭게 SEO 관련 설정을 추가하는 부분은 아닙니다.
이제 SEO 가 잘 적용되는지 확인해보기 위해, Google Search Console 서비스에 등록합니다. 다만 이를 등록함을 통해 다음 정보를 확인할 수 있습니다.
- Google에서 사이트를 찾아 크롤링할 수 있는지 확인합니다.
- 색인 생성 문제를 해결하고 새로운 콘텐츠나 업데이트된 콘텐츠의 색인을 다시 생성하도록 요청합니다.
- 사이트의 Google 검색 트래픽 데이터(Google 검색에 사이트가 표시되는 빈도, 사이트를 표시하는 검색어, 검색 사용자가 검색어를 클릭하여 연결하는 빈도 등)를 확인합니다.
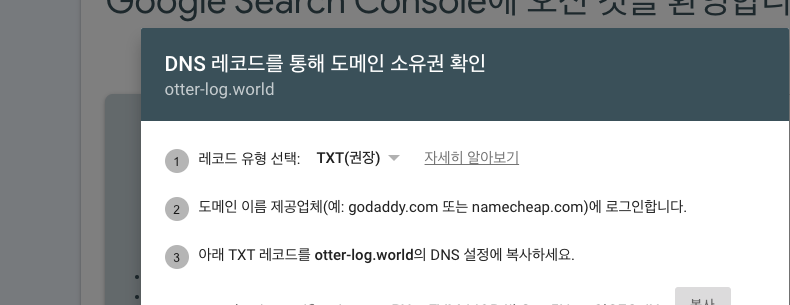
해당 도메인을 호스팅하는 쪽에 dns 설정을 추가해주어야 합니다. 저는 aws Route를 이용했었기 때문에 다음과 같이 등록했습니다.

info 에 키를 등록해주면 진행됩니다!